
robots.txtって何ですか?作るとどんなメリットがあるんですか?作り方も教えてほしいです
本記事では上記のような疑問を解決します
本記事でわかること
・robots.txtが何かわかる
・robots.txtの作り方がわかる
・robots.txtを作るメリットがわかる
目次
robots.txtとは
「robots.txt」とは、検索エンジンのクローラー(ロボット)に対して、Webサイトのどのページやディレクトリをクロール(巡回)してよいか、またはしてはいけないかを指示するためのテキストファイルです。
上記の通りでして、robots.txtは特定のページへのGoogleのクローラーのアクセス制限を記述するファイルのことです。
//robots.txtの正しい設置場所
https://example.com/robots.txt上記のようにサーバーの最上位のディレクトリにファイルを入れるようにしてクロールを制御します。
//サブディレクトリでは制御できない
https://example.com/something/robots.txt
//異なるサブドメインでも制御できない
https://sub.example.com/robots.txt反対に上記のようにサブディレクトリに置いたり、異なるサブドメインに置いても制御はできないためご注意下さい。
robots.txtのメリット
ブログで上位表示させる必要が無いページへの巡回回数を減らし、クローラーに効率的に重要なページへのクロールを促すことができることです。
Googleのクローラーが1回にクロール出来る回数には上限(クロールバジェットと言います)がありますが、クロールしなくてよいページへのクロールをしないことでクロールバジェットの無駄使いをしなくていいということですね。
特定のページに指定することもできますし、カテゴリーやディレクトリごとの制御も可能です。
noindexとの違い
robots.txt は「ページを見に来ないで」とクローラーに伝えるものですが、noindex は「ページを見てもいいけど、検索結果に載せないで」と伝えるものです。
つまり、robots.txt は“クロールの制御”、noindex は“インデックスの制御”です。
robots.txt→検索エンジンに登録(インデックス)自体はされますし、ユーザーも読むことができます。
noindex→インデックス自体を拒否するため、自然検索などでの流入は無くなります
| robots.txt | noindex |
| テキストファイル | meta要素 |
| ファイルタイプは問わない | HTML向け |
| ホスト、パス全体に運用が可能 | 個別ページ向けに運用 |
| クロールをブロックする | インデックスをブロックする |
robots.txtの書き方
robots.txtの基本的な書き方は以下の通り。
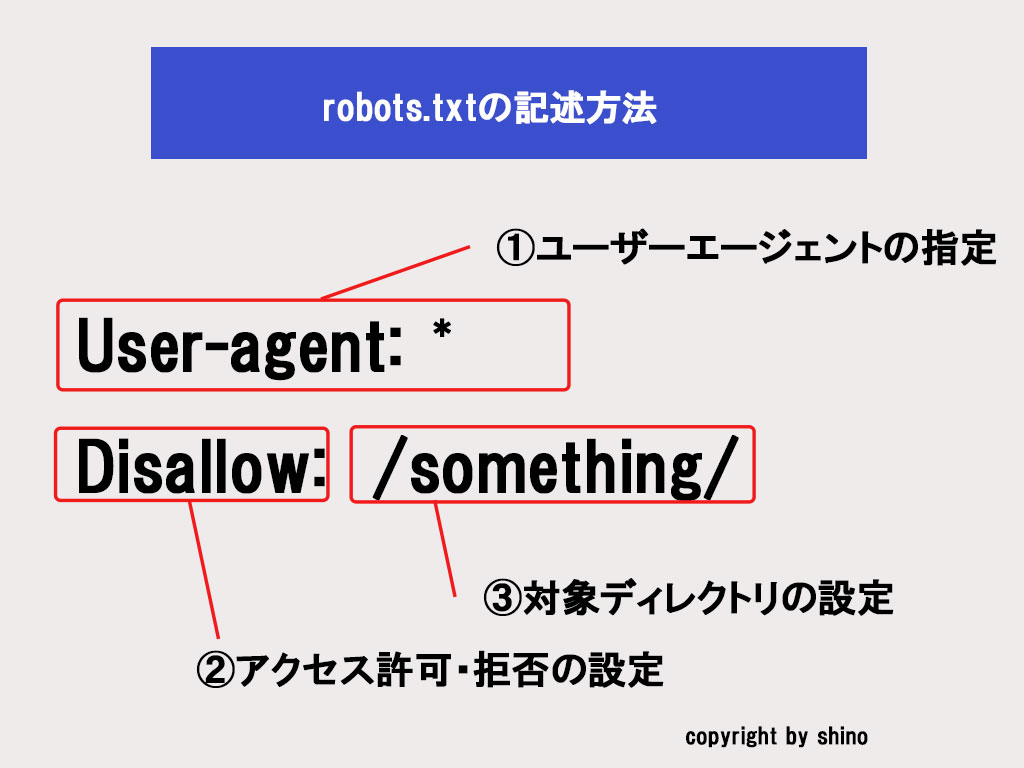
上記の内容について解説します。
User-agentとは
User-agentとは、何らかの通信のためにエンドユーザー側で利用される機材やプログラムのことです。
と言われても意味が分かりづらいですよね。
要は「どんなブラウザやデバイスでウェブサイトに訪問しているか」を表すものがUser-Agentと呼ばれるものです。
User→利用者
Agent→代理人
という意味ですが、ユーザーが使っているソフトウェア(ブラウザやデバイスの事を指す)の事をUser-Agentと言います。
例えば以下をご覧ください。
User-Agentの例
User-Agent: Mozilla/5.0
上記ではMozilla FireFoxのVersion5.0のブラウザでサイトを訪問している、ということです。
話をrobots.txtの書き方に戻します。
User-agent:*
Disallow:/ここでUser-agentは「*」となっていますが、これは「全てのユーザーエージェントを対象にする」という意味になります。
何か特別な理由が無い限りはここは「*」で問題ありません。
ちなみに、Googleが運用しているクローラー(Googlebot)のユーザーエージェントは以下です。
・パソコン用Googlebot:Googlebot
・スマートフォン用Googlebot:Googlebot
・画像用Googlebot:Googlebot-Image
・Adsense用クローラー:Mediapartners-Google
もし何かしらの理由でGoogleの運用しているクローラーからのアクセスを拒否したい場合は上記のユーザーエージェントを入力すればOKです。
Allow/Disallowとは
次にAllowとDisallowの違いについて解説します。
| 指示 | 意味 |
| Allow | アクセスを許可するという意味。デフォルトの状態では全てアクセスが許可されているため記述は不要。Disallowでブロックしている一部を上書きする際に使用する |
| Disallow | アクセスを拒否するという意味。 |
基本的にはアクセス拒否を意味するDisallowを使うようにするといいですね。
User-agent:*
Disallow:/つまり上記のコードの例では「全ユーザーエージェントのクローラーに対して、「/」ディレクトリ以下の前ページのアクセスを禁止する」という意味になっています。
以下に何種類か書き方を記載します。
//サイト全体のクロールを禁止する書き方
Disallow: ///特定のディレクトリのクロールを禁止する書き方
Disallow: /category/
※上記の「/category/」は例であり、ブログやサイトのディレクトリによって変わりますrobots.txtの確認方法
作成したrobots.txtが正しい書き方で書かれているかを確認するには、Google Search Consoleのrobots.txtテスターで確認できます。
まずはアクセスしてみましょう。
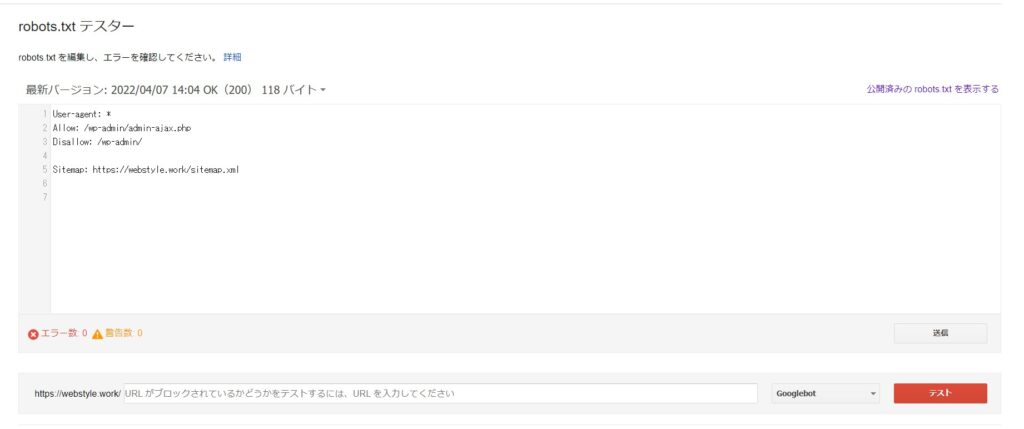
アクセスすると上記のような画面になると思います。
次に作成したrobots.txtの文章を貼りつけます。

今回は「profile-4」というディレクトリをDisallowに設定しました。
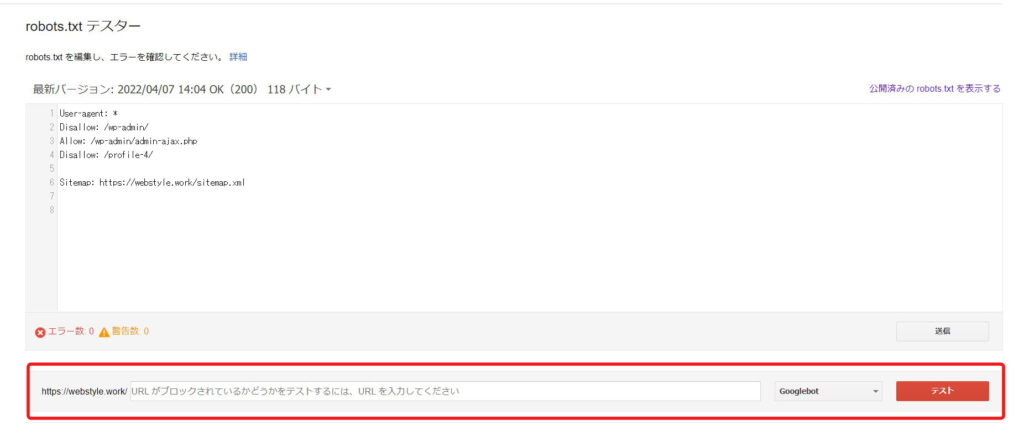
ここでは
webstyle.work/profile-4
と入力しました。

そしてテストを押して上記のようにブロック済みと表示されれば正しく記述されている事が分かります。
※ただ、ご自身が契約しているサーバーのFTPを使用してドメインの最上部にrobots.txtのファイルを設置する必要がありますので、その点だけご注意ください。
robots.txtで注意するべき点
最後にrobotx.txtで注意するべき点について紹介します。
robots.txtは誰でも見れる
robots.txtは誰でも見ることができます。
それこそ、見たいサイトのURLの末尾に「robots.txt」と打ちこめばそのサイトのrobots.txtを見ることができるので他の人のサイトやブログを見て参考にしてみても良いのではないでしょうか。
ただ、誰でも見ることができるため、重要なページや管理者用のページなどリスクのあるページのURLは記載しないようにしましょう。
JavaScriptやCSS、画像ファイルへのアクセスは制限しない
クローラーに対して、JavaScriptやCSS、画像ファイルへのアクセスを制限してしまうと正しくインデックスされないことがあったり、不具合が生じることがあったりするなど不都合が生じる可能性があります。
ブログのコンテンツに必要なリソースやファイルにはアクセス出来るように下手に制限しないほうが良いですね。
まとめ:robots.txtで適切なSEO内部対策を!
というわけで本記事ではrobots.txtがそもそも何なのか、そして書き方やメリットについて解説しました。
robots.txtは少し難しく感じるかもしれませんが、書くこと自体はシンプルですし、適切に記載することで有効なSEO内部対策にもなります。
もし、より効率的にGooglebotにクロールしてほしい場合などは積極的に活用してみてはいかがでしょうか。
というわけで本日の記事は以上です( ͡° ͜ʖ ͡°)

